 PDF(242 KB)
PDF(242 KB)

Graph Attention Networks for Multiple Pairs of Entities and Aspects Sentiment Analysis in Long Texts
Jie LENG, Xijin TANG
Journal of Systems Science and Information ›› 2022, Vol. 10 ›› Issue (3) : 203-215.
PDF(242 KB)
PDF(242 KB)
Graph Attention Networks for Multiple Pairs of Entities and Aspects Sentiment Analysis in Long Texts
The goal of sentiment analysis is to detect the opinion polarities of people towards specific targets. For fine-grained analysis, aspect-based sentiment analysis (ABSA) is a challenging subtask of sentiment analysis. The goals of most literature are to judge sentiment orientation for a single aspect, but the entities aspects belong to are ignored. Sequence-based methods, such as LSTM, or tagging schemas, such as BIO, always rely on relative distances to target words or accurate positions of targets in sentences. It will require more detailed annotations if the target words do not appear in sentences. In this paper, we discuss a scenario where there are multiple entities and shared aspects in multiple sentences. The task is to predict the sentiment polarities of different pairs, i.e., (entity, aspect) in each sample, and the target entities or aspects are not guaranteed to exist in texts. After converting the long sequences to dependency relation-connected graphs, the dependency distances are embedded automatically to generate contextual representations during iterations. We adopt partly densely connected graph convolutional networks with multi-head attention mechanisms to judge the sentiment polarities for pairs of entities and aspects. The experiments conducted on a Chinese dataset demonstrate the effectiveness of the method. We also explore the influences of different attention mechanisms and the connection manners of sentences on the tasks.
sentiment analysis / dependency analysis / graph convolution networks / attention mechanism {{custom_keyword}} /
Table 1 Comparisons of sequence-based and basic graph models on the Baby Care dataset |
| Metrics | LSTM | ATAE-LSTM | GCNs | DGCNs | D1GCNs | NED1GATs |
| Accuracy | 75.44 | 76.18 | 44.00 | 75.17 | 75.52 | 78.27 |
| Precision | 75.44 | 76.17 | 34.36 | 75.33 | 75.52 | 78.73 |
| Recall | 75.44 | 76.17 | 33.90 | 75.12 | 75.52 | 78.32 |
| F1 | 75.44 | 76.17 | 32.90 | 75.10 | 75.52 | 78.21 |
Table 2 Results of ablation study of the model NED1GATs dataset |
| No. | Modification | Accuracy | Precision | Recall | F1 |
| Proposed NED1GATs | 78.27 | 78.73 | 78.32 | 78.21 | |
| 1 | remove the attention head of the entity and aspect relevance (ND1GATs) | 77.57 | 77.58 | 77.57 | 77.57 |
| 2 | remove the attention head of the node similarity (ED1GATs) | 77.40 | 77.42 | 77.41 | 77.40 |
| 3 | remove the dense connection (NEGATs) | 76.56 | 76.71 | 76.53 | 76.51 |
| 4 | remove the Bi-LSTM: without initial semantic information | 76.40 | 76.40 | 76.43 | 76.37 |
Table 3 Comparisons of different attention mechanisms for graph models on the task |
| Metrics | GCNs | DCGCNs | |||||||
| - | - | ||||||||
| Accuracy | 44 | 76.78 | 49.89 | 76.29 | 75.17 | 74.77 | 51.14 | 75.8 | |
| Precision | 34.36 | 76.99 | 49.81 | 76.31 | 75.33 | 75.05 | 51.17 | 75.8 | |
| Recall | 33.9 | 76.81 | 49.82 | 76.3 | 75.12 | 74.72 | 51.17 | 75.79 | |
| F1 | 32.9 | 76.75 | 49.41 | 76.29 | 75.1 | 74.67 | 51.1 | 75.8 | |
Table 4 Comparisons of different connection manners between sentences |
| Metrics | NEGATs | NED1GATs | NEDGATs | |||||
| ROOT | NEXT | ROOT | NEXT | ROOT | NEXT | |||
| Accuracy | 77.59 | 76.56 | 78.11 | 78.27 | 77.65 | 75.64 | ||
| Precision | 77.67 | 76.71 | 78.11 | 78.73 | 77.68 | 76.29 | ||
| Recall | 77.57 | 76.53 | 78.11 | 78.32 | 77.63 | 75.57 | ||
| F1 | 77.57 | 76.51 | 78.11 | 78.21 | 77.63 | 75.45 | ||
| 1 |
{{custom_citation.content}}
{{custom_citation.annotation}}
|
| 2 |
Phan M H, Philip O O. Modelling context and syntactical features for aspect-based sentiment analysis. Proceedings of the 58th Annual Meeting of the Association for Computational Linguistics, Association for Computational Lin-Guistics, Online, 2020: 3211-3220.
{{custom_citation.content}}
{{custom_citation.annotation}}
|
| 3 |
Wang Y Q, Huang M L, Zhu X Y, et al. Attention-based LSTM for aspect-level sentiment classification. Proceedings of the 2016 Conference on Empirical Meth-ods in Natural Language Processing, Association for Computational Linguistics, Austin, 2016: 606-615.
{{custom_citation.content}}
{{custom_citation.annotation}}
|
| 4 |
Tang D Y, Qin B, Feng X C, et al. Effective LSTMs for target-dependent senti-ment classification. Proceedings of COLING 2016, the 26th International Conference on Computational Linguistics: Technical Papers, The COLING 2016 Organizing Committee, Osaka, 2016: 3298-3307.
{{custom_citation.content}}
{{custom_citation.annotation}}
|
| 5 |
Sun K, Zhang R C, Mensah S, et al. Aspect-level sentiment analysis via convolution over dependency tree. Proceedings of the 2019 Conference on Empirical Methods in Natural Language Processing and the 9th International Joint Conference on Natural Language Processing (EMNLP-IJCNLP), Association for Computational Linguistics, Hong Kong, 2019: 5678-5687.
{{custom_citation.content}}
{{custom_citation.annotation}}
|
| 6 |
Wang K, Shen W Z, Yang Y Y, et al. Relational graph attention network for aspect-based sentiment analysis. Proceedings of the 58th Annual Meeting of the Association for Computational Linguistics, Association for Computa-tional Linguistics, Online, 2020: 3229-323.
{{custom_citation.content}}
{{custom_citation.annotation}}
|
| 7 |
Liu J M, Zhang Y. Attention modeling for targeted sentiment. Proceedings of the 15th Conference of the European Chapter of the Association for Computational Linguistics, Association for Computational Linguistics, Valencia, 2017, 2: 572-577.
{{custom_citation.content}}
{{custom_citation.annotation}}
|
| 8 |
Huang B X, Carley K M. Syntax-aware aspect level sentiment classification with graph attention networks. Proceedings of the 2019 Conference on Empirical Methods in Natural Language Processing and the 9th International Joint Conference on Natural Language Processing (EMNLP-IJCNLP), Association for Computational Linguistics, Hong Kong, 2019: 5468-5476.
{{custom_citation.content}}
{{custom_citation.annotation}}
|
| 9 |
Zhang C, Li Q C, Song D W. Aspect-based sentiment classification with aspect-specific graph convolutional networks. Proceedings of the 2019 Conference on Empirical Methods in Natural Language Processing and the 9th International Joint Conference on Natural Language Processing (EMNLP-IJCNLP), Association for Computational Linguistics, Hong Kong, 2019: 4567-4577.
{{custom_citation.content}}
{{custom_citation.annotation}}
|
| 10 |
Tang D Y, Qin B, Liu T. Aspect level sentiment classification with deep memory network. Proceedings of the 2016 Conference on Empirical Methods in Natural Language Processing, Association for Computational Linguistics, Austin, 2016: 214-224.
{{custom_citation.content}}
{{custom_citation.annotation}}
|
| 11 |
Yang, M, Tu W T, Wang J X, et al. Attention based LSTM for target dependent sentiment classification. Proceedings of the Thirty-First AAAI Conference on Artificial Intelligence. AAAI Press, San Francisco, 2017: 5013-5014.
{{custom_citation.content}}
{{custom_citation.annotation}}
|
| 12 |
Ji Y, Liu H, He B, et al. Diversified multiple instance learning for document-level multi-aspect sentiment classification. Proceedings of the 2020 Conference on Empirical Methods in Natural Language Processing, Association for Computational Linguistics, Online, 2020: 7012-7023.
{{custom_citation.content}}
{{custom_citation.annotation}}
|
| 13 |
Shi T, Rakesh V, Wang S, et al. Document-level multi-aspect sentiment classifica-tion for online reviews of medical experts. Proceedings of the 28th ACM Interna-tional Conference on Information and Knowledge Management. New York: Association for Computing Machinery, 2019: 2723-2731.
{{custom_citation.content}}
{{custom_citation.annotation}}
|
| 14 |
{{custom_citation.content}}
{{custom_citation.annotation}}
|
| 15 |
{{custom_citation.content}}
{{custom_citation.annotation}}
|
| 16 |
{{custom_citation.content}}
{{custom_citation.annotation}}
|
| 17 |
{{custom_citation.content}}
{{custom_citation.annotation}}
|
| 18 |
{{custom_citation.content}}
{{custom_citation.annotation}}
|
| 19 |
{{custom_citation.content}}
{{custom_citation.annotation}}
|
| 20 |
{{custom_citation.content}}
{{custom_citation.annotation}}
|
| 21 |
{{custom_citation.content}}
{{custom_citation.annotation}}
|
| 22 |
Velickovic P, Cucurull G, Casanova A, et al. Graph attention networks. arXiv preprint arXiv: 1710.10903, 2017.
{{custom_citation.content}}
{{custom_citation.annotation}}
|
| 23 |
{{custom_citation.content}}
{{custom_citation.annotation}}
|
| 24 |
{{custom_citation.content}}
{{custom_citation.annotation}}
|
| 25 |
{{custom_citation.content}}
{{custom_citation.annotation}}
|
| 26 |
{{custom_citation.content}}
{{custom_citation.annotation}}
|
| 27 |
{{custom_citation.content}}
{{custom_citation.annotation}}
|
| 28 |
{{custom_citation.content}}
{{custom_citation.annotation}}
|
| 29 |
{{custom_citation.content}}
{{custom_citation.annotation}}
|
| 30 |
{{custom_citation.content}}
{{custom_citation.annotation}}
|
| 31 |
Liu S, Li W, Wu Y F, et al. Jointly modeling aspect and sentiment with dynamic heter-ogeneous graph neural networks. arXiv: 2004.0642, 2020.
{{custom_citation.content}}
{{custom_citation.annotation}}
|
| 32 |
{{custom_citation.content}}
{{custom_citation.annotation}}
|
| 33 |
{{custom_citation.content}}
{{custom_citation.annotation}}
|
| 34 |
{{custom_citation.content}}
{{custom_citation.annotation}}
|
| 35 |
{{custom_citation.content}}
{{custom_citation.annotation}}
|
| {{custom_ref.label}} |
{{custom_citation.content}}
{{custom_citation.annotation}}
|
The computations were done on the high performance computers ofState Key Laboratory of Scientific and Engineering Computing, Chinese Academy of Sciences, and took approximately 500 hours to run. The authors would like to thank the anonymousreviewers for their valuable comments.
PDF(242 KB)
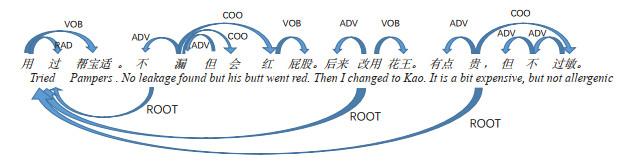
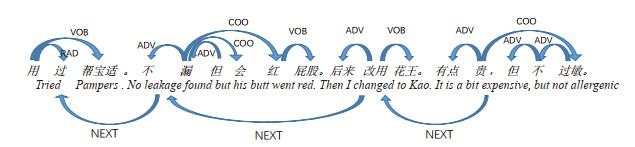
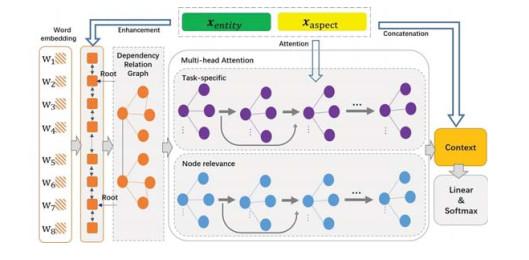
 Figure 1 A dependency syntax tree for four sentences. Edges represent conventional intra-sentential dependencies and the connections between the "root" words of adjacent sentencesFigure 2 A dependency tree for four sentences. Edges represent conventional intra-sentential dependencies. The "root" words of adjacent sentences are connected in orderFigure 3 Structure of the proposed partly densely connected graph attention network with two attention mechanisms
Figure 1 A dependency syntax tree for four sentences. Edges represent conventional intra-sentential dependencies and the connections between the "root" words of adjacent sentencesFigure 2 A dependency tree for four sentences. Edges represent conventional intra-sentential dependencies. The "root" words of adjacent sentences are connected in orderFigure 3 Structure of the proposed partly densely connected graph attention network with two attention mechanisms Table 1 Comparisons of sequence-based and basic graph models on the Baby Care datasetTable 2 Results of ablation study of the model NED1GATs datasetTable 3 Comparisons of different attention mechanisms for graph models on the taskTable 4 Comparisons of different connection manners between sentences
Table 1 Comparisons of sequence-based and basic graph models on the Baby Care datasetTable 2 Results of ablation study of the model NED1GATs datasetTable 3 Comparisons of different attention mechanisms for graph models on the taskTable 4 Comparisons of different connection manners between sentences/
| 〈 |
|
〉 |




{kind=link}
{kind=link}
{kind=link}